Знакомство с NVIDIA RTX PRO 6000 Blackwell
В марте 2025 года NVIDIA представила линейку профессиональных видеокарт RTX PRO 6000 на архитектуре Blackwell. Это не игровая карта — она создана для профессионалов, работающих с ИИ, научными вычислениями, 3D-рендерингом и обработкой видео.
Зачем NVIDIA выпустила эту видеокарту
До появления RTX PRO 6000 у профессионалов был разрыв между потребительскими картами (RTX 5090 с 32 ГБ VRAM) и серверными ускорителями (A100/H100 с 80 ГБ). RTX 5090 не хватало памяти для больших моделей, а серверные GPU стоили десятки тысяч долларов и требовали специальной инфраструктуры.
RTX PRO 6000 закрывает этот разрыв: 96 ГБ GDDR7 памяти в формате десктопной видеокарты. Это позволяет запускать модели на 70B+ параметров прямо на рабочей станции, без облака и без серверной стойки.
Целевая аудитория
- AI/ML-инженеры — локальная разработка и тестирование LLM, файн-тюнинг моделей
- Дата-сайентисты — работа с большими датасетами через RAPIDS и CUDA
- 3D-художники и архитекторы — рендеринг сложных сцен с трассировкой лучей
- Видеопродакшн — обработка 4K/8K контента с аппаратным кодированием
- Научные вычисления — симуляции, геномика, финансовое моделирование
- Провайдеры GPU-инфраструктуры — предоставление GPU-мощностей для инференса ИИ-моделей в аренду
Характеристики RTX PRO 6000 Blackwell Workstation Edition
| Параметр | Значение |
|---|---|
| Архитектура | NVIDIA Blackwell (GB202) |
| CUDA-ядра | 24 064 |
| Тензорные ядра | 5-го поколения, 752 шт. |
| RT-ядра | 4-го поколения, 188 шт. |
| Потоковые мультипроцессоры (SM) | 188 |
| Видеопамять | 96 ГБ GDDR7 с ECC |
| Шина памяти | 512 бит |
| Пропускная способность памяти | 1792 ГБ/с |
| Эффективная частота памяти | 1750 МГц (28 Гбит/с на контакт) |
| AI-производительность | 4000 TOPS (FP4, со спарсити) |
| FP32-производительность | 125 TFLOPS |
| RT-производительность | 380 TFLOPS |
| Транзисторов | 92.2 млрд |
| Площадь кристалла | 750 мм² |
| Интерфейс | PCIe 5.0 x16 |
| Видеовыходы | 4× DisplayPort 2.1 |
| Видеокодирование | 4× NVENC 9-го поколения |
| Видеодекодирование | 4× NVDEC 6-го поколения |
| TDP | 600 Вт |
Полные характеристики и даташит доступны на официальной странице NVIDIA RTX PRO 6000.
Ключевое преимущество для ИИ-задач — это 96 ГБ GDDR7 с пропускной способностью 1792 ГБ/с. Для сравнения: RTX 5090 имеет 32 ГБ GDDR7, а предыдущая профессиональная RTX 6000 Ada (Lovelace) — 48 ГБ GDDR6. RTX PRO 6000 удваивает объём памяти и значительно увеличивает bandwidth, что критично для инференса больших языковых моделей.
Модели для тестирования
Мы запустили три модели разных архитектур на отдельных видеокартах RTX PRO 6000, каждая в своём Docker-контейнере через vLLM:
| Модель | Тип | Всего параметров | Активных параметров | Квантизация | Контекст (макс.) |
|---|---|---|---|---|---|
| Qwen3.5-122B-A10B | MoE (256 экспертов) | 122B | 10B | NVFP4 | 262K |
| GLM-4.6V | MoE | 106B | 32B | NVFP4 | 128K (до 200K) |
| Llama 4 Scout 17B-16E | MoE (16 экспертов) | 109B | 17B | W4A16 | 10M (до 512K практически) |
Все три модели используют архитектуру Mixture of Experts (MoE). В отличие от обычных (dense) моделей, где каждый токен проходит через все параметры, MoE-модель содержит множество «экспертов» — отдельных блоков нейронной сети. Маршрутизатор (router) для каждого токена выбирает лишь несколько экспертов из всего набора.
Важно понимать: MoE-модель загружается в видеопамять целиком — все параметры всех экспертов должны находиться в VRAM. Но при обработке каждого конкретного токена активируется только малая часть из них. Например, Qwen3.5-122B-A10B имеет 122B параметров и занимает ~75 ГБ VRAM, но на каждый токен задействует только 10B параметров из 256 экспертов. Это означает, что скорость инференса определяется размером активной части (10B), а не общим размером модели (122B), при этом качество ответов соответствует модели на 122B параметров.
Запуск моделей через vLLM в Docker Compose
Для запуска моделей мы используем vLLM — высокопроизводительный бэкенд для инференса LLM с поддержкой PagedAttention, continuous batching и автоматического управления KV-кешем.
Общие параметры запуска
Прежде чем разбирать конфигурацию каждой модели, рассмотрим параметры, которые встречаются во всех трёх сервисах:
| Параметр | Описание |
|---|---|
--trust-remote-code |
Разрешает выполнение кастомного кода из репозитория модели на HuggingFace. Необходим для моделей с нестандартной архитектурой |
--gpu-memory-utilization 0.95-0.97 |
Доля VRAM, которую vLLM может использовать. Остаток резервируется под CUDA-контекст и системные нужды |
--enable-prefix-caching |
Кеширует KV-состояния общих префиксов между запросами. Ускоряет обработку повторяющихся системных промптов |
--enable-chunked-prefill |
Разбивает длинные промпты на чанки и обрабатывает их параллельно с генерацией других запросов. Снижает TTFT |
--enable-auto-tool-choice |
Включает автоматический выбор инструментов (function calling) |
--served-model-name |
Имя модели, по которому она будет доступна через API |
--port |
Порт для HTTP API |
Qwen3.5-122B-A10B (NVFP4)
vllm-qwen35-122b:
image: vllm/vllm-openai:v0.18.1
volumes:
- ~/.cache/huggingface:/root/.cache/huggingface
environment:
- HUGGING_FACE_HUB_TOKEN=${HUGGING_FACE_HUB_TOKEN}
entrypoint: ["/bin/bash", "-c"]
command:
- |
pip install "transformers>=5.0.0" && \
vllm serve RedHatAI/Qwen3.5-122B-A10B-NVFP4 \
--trust-remote-code \
--gpu-memory-utilization 0.95 \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--served-model-name qwen3.5-122b \
--max-model-len 32768 \
--moe-backend flashinfer_cutlass \
--enable-prefix-caching \
--enable-chunked-prefill \
--max-num-seqs 64 \
--port 8000
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ["0"]
capabilities: [gpu]
ipc: host
restart: unless-stoppedСпецифичные параметры:
| Параметр | Описание |
|---|---|
pip install "transformers>=5.0.0" |
Модель Qwen3.5 требует новую версию transformers, которой нет в базовом образе vLLM |
--reasoning-parser qwen3 |
Парсер для режима reasoning (цепочка рассуждений). Qwen3.5 поддерживает thinking-режим с тегами <think> |
--tool-call-parser hermes |
Формат парсинга вызовов функций — Hermes-стиль, совместимый с Qwen |
--max-model-len 32768 |
Максимальная длина контекста ограничена 32K токенами (подробнее в разделе про расчёт контекста) |
--moe-backend flashinfer_cutlass |
Бэкенд для MoE-слоёв. FlashInfer + CUTLASS обеспечивает оптимальную производительность для MoE-моделей на Blackwell |
--max-num-seqs 64 |
Максимум 64 одновременных запроса в батче |
GLM-4.6V (NVFP4)
vllm-glm46v-nvfp4:
image: vllm/vllm-openai:v0.18.1
volumes:
- ~/.cache/huggingface:/root/.cache/huggingface
environment:
- HUGGING_FACE_HUB_TOKEN=${HUGGING_FACE_HUB_TOKEN}
- VLLM_ENGINE_ITERATION_TIMEOUT_S=600
entrypoint: ["/bin/bash", "-c"]
command:
- |
pip install --upgrade "huggingface-hub>=0.26.0" "transformers>=5.0.0" && \
vllm serve GadflyII/GLM-4.6V-NVFP4 \
--trust-remote-code \
--max-model-len 131072 \
--gpu-memory-utilization 0.95 \
--kv-cache-dtype fp8 \
--served-model-name glm-4.6v \
--max-num-seqs 8 \
--enable-prefix-caching \
--enable-chunked-prefill \
--reasoning-parser deepseek_r1 \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--port 8004
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ["1"]
capabilities: [gpu]
ipc: host
restart: unless-stoppedСпецифичные параметры:
| Параметр | Описание |
|---|---|
VLLM_ENGINE_ITERATION_TIMEOUT_S=600 |
Увеличенный таймаут итерации движка (10 минут). GLM-4.6V — тяжёлая модель, и при длинных промптах prefill может занимать значительное время |
pip install --upgrade "huggingface-hub>=0.26.0" |
Требуется обновлённая версия HF Hub для загрузки модели |
--max-model-len 131072 |
Контекст 128K токенов — максимум для GLM-4.6V в обучении |
--kv-cache-dtype fp8 |
KV-кеш хранится в формате FP8 вместо FP16. Это вдвое сокращает потребление памяти на кеш, позволяя вместить больший контекст |
--max-num-seqs 8 |
Только 8 одновременных запросов — GLM-4.6V значительно тяжелее, 32B активных параметров потребляют больше VRAM |
--reasoning-parser deepseek_r1 |
Парсер reasoning в стиле DeepSeek R1 — GLM-4.6V использует аналогичный формат цепочки рассуждений |
Llama 4 Scout 17B-16E (W4A16)
vllm-llama4-scout:
image: vllm/vllm-openai:v0.18.1
volumes:
- ~/.cache/huggingface:/root/.cache/huggingface
environment:
- HUGGING_FACE_HUB_TOKEN=${HUGGING_FACE_HUB_TOKEN}
- VLLM_DISABLE_COMPILE_CACHE=1
entrypoint: ["/bin/bash", "-c"]
command:
- |
vllm serve RedHatAI/Llama-4-Scout-17B-16E-Instruct-quantized.w4a16 \
--trust-remote-code \
--gpu-memory-utilization 0.97 \
--served-model-name llama-4-scout \
--max-model-len 131072 \
--enable-prefix-caching \
--enable-chunked-prefill \
--max-num-seqs 64 \
--limit-mm-per-prompt '{"image": 10}' \
--enable-auto-tool-choice \
--tool-call-parser llama3_json \
--override-generation-config '{"attn_temperature_tuning": true}' \
--port 8003
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ["2"]
capabilities: [gpu]
ipc: host
restart: unless-stoppedСпецифичные параметры:
| Параметр | Описание |
|---|---|
VLLM_DISABLE_COMPILE_CACHE=1 |
Отключает кеш компиляции CUDA-графов. Необходимо для Llama 4 из-за особенностей архитектуры MoE с 16 экспертами |
--gpu-memory-utilization 0.97 |
Более агрессивное использование VRAM (97%) — Llama 4 Scout в W4A16 квантизации достаточно компактна |
--max-model-len 131072 |
128K токенов контекста. Llama 4 Scout поддерживает до 10M токенов, но на одной карте это нереально |
--limit-mm-per-prompt '{"image": 10}' |
Ограничение: максимум 10 изображений на один запрос. Llama 4 Scout — мультимодальная модель |
--tool-call-parser llama3_json |
Парсер function calling в формате Llama 3 JSON |
--override-generation-config '{"attn_temperature_tuning": true}' |
Включает температурную настройку внимания — улучшает качество генерации на длинных контекстах, рекомендовано Meta |
--max-num-seqs 64 |
До 64 параллельных запросов — модель легче за счёт W4A16 квантизации |
Расчёт контекста и KV-кеш
Почему контекст ограничен
Вы могли заметить, что максимальный контекст моделей в наших конфигурациях значительно меньше, чем заявленный разработчиками:
| Модель | Макс. контекст модели | Наш --max-model-len |
Причина |
|---|---|---|---|
| Qwen3.5-122B-A10B | 262K | 32 768 | Ограничение VRAM под KV-кеш + параллельные запросы |
| GLM-4.6V | 128K–200K | 131 072 | Используется FP8 KV-кеш для экономии памяти |
| Llama 4 Scout | 10M | 131 072 | Физически невозможно вместить больше на 96 ГБ |
Дело в том, что при инференсе GPU должен хранить в памяти одновременно:
- Веса модели — фиксированный объём
- KV-кеш — растёт линейно с длиной контекста × количество запросов
- Активации — временные данные при вычислениях
- Оверхед vLLM — PagedAttention, метаданные, CUDA-контекст
Формула расчёта KV-кеша
Для одного токена в одном запросе KV-кеш занимает:
KV_per_token = 2 × N_layers × N_kv_heads × D_head × dtype_sizeГде:
2— ключ (K) и значение (V)N_layers— количество слоёв трансформераN_kv_heads— количество голов внимания для KV (при GQA меньше, чем Q-голов)D_head— размерность одной головы (обычно 128)dtype_size— размер одного числа в байтах (FP16 = 2, FP8 = 1, FP4 ≈ 0.5)
Общий объём KV-кеша:
KV_total = KV_per_token × max_context_len × max_concurrent_requestsРасчёт для наших моделей
Qwen3.5-122B-A10B (NVFP4 веса, FP16 KV-кеш):
- 64 слоя, 4 KV-головы (GQA), D_head = 128, dtype = FP16 (2 байта)
- KV на токен = 2 × 64 × 4 × 128 × 2 = 131 072 байт ≈ 128 КБ/токен
- При контексте 32K и 64 запросах: 128 КБ × 32 768 × 64 ≈ 256 ГБ — это больше, чем 96 ГБ VRAM
- Реально vLLM использует PagedAttention и динамически распределяет память, поэтому 64 запроса не будут одновременно использовать полный контекст
GLM-4.6V (NVFP4 веса, FP8 KV-кеш):
- Благодаря
--kv-cache-dtype fp8размер KV-кеша сокращается вдвое - Это позволяет вместить контекст 128K при 8 параллельных запросах
Llama 4 Scout (W4A16 веса, FP16 KV-кеш):
- 48 слоёв, 8 KV-голов (GQA), D_head = 128, dtype = FP16
- KV на токен = 2 × 48 × 8 × 128 × 2 = 196 608 байт ≈ 192 КБ/токен
- При контексте 128K: 192 КБ × 131 072 ≈ 24 ГБ на один запрос
Таблица оверхеда vLLM
При планировании контекста важно учитывать, что не вся VRAM доступна для KV-кеша:
| Компонент | Примерный объём | Примечание |
|---|---|---|
| Веса модели (NVFP4/W4A16) | 43–75 ГБ | Зависит от размера и квантизации |
| CUDA-контекст | 1–3 ГБ | Инициализация драйвера и рантайма |
| Активации и буферы vLLM | 2–5 ГБ | PagedAttention metadata, block tables |
| Резерв (1 - gpu-memory-utilization) | 3–5 ГБ | Защита от OOM |
| Доступно для KV-кеша | 10–45 ГБ | Остаток от 96 ГБ |
Максимальный контекст на одной RTX PRO 6000
Исходя из доступной памяти, вот максимальные контексты при одном запросе:
| Модель | Веса в VRAM | Доступно для KV | Макс. контекст (1 запрос) | Макс. контекст (8 запросов) |
|---|---|---|---|---|
| Qwen3.5-122B-A10B | ~75 ГБ | ~13 ГБ | ~104K | ~13K |
| GLM-4.6V (FP8 KV) | ~62 ГБ | ~26 ГБ | ~200K | ~25K |
| Llama 4 Scout | ~43 ГБ | ~45 ГБ | ~240K | ~30K |
Эти значения приблизительные. Реальные цифры зависят от конкретной реализации модели и версии vLLM.
Именно поэтому мы занижаем --max-model-len — чтобы несколько пользователей могли одновременно отправлять запросы без задержек и ошибок OOM. Лучше стабильный сервис с контекстом 32K для 64 пользователей, чем нестабильный с 256K для одного.
Тестирование
Бенчмарки качества моделей
Результаты стандартных бенчмарков взяты из официальных карточек моделей. Нет смысла прогонять MMLU или HumanEval самостоятельно — разработчики уже сделали это в контролируемых условиях.
| Бенчмарк | Что тестирует | Qwen3.5-122B-A10B | GLM-4.6 | Llama 4 Scout |
|---|---|---|---|---|
| MMLU-Pro | Знания и рассуждения (12K вопросов) | 86.1% | ~78% | 74.3% |
| GPQA Diamond | Экспертные вопросы PhD-уровня | 85.5% | ~65% | 57.2% |
| LiveCodeBench | Генерация кода (свежие задачи) | ~55% | ~50% | 32.8% |
| SWE-bench Verified | Реальные баг-фиксы в open source | 72.4% | ~45% | — |
| MATH | Математические задачи | ~75% | ~70% | 50.3% |
| MGSM | Мультиязычная математика | ~90% | ~85% | 90.6% |
| MMMU | Мультимодальное понимание | ~65% | ~68% | 69.4% |
| DocVQA | Понимание документов | — | ~90% | 94.4% |
| ChartQA | Понимание графиков | — | ~85% | 88.8% |
Данные Llama 4 Scout — из официальной MODEL_CARD Meta. Qwen3.5-122B-A10B — из карточки модели на HuggingFace. GLM-4.6 — из документации Zhipu AI.
Qwen3.5-122B-A10B — лидер по качеству рассуждений и кода. MMLU-Pro 86.1% и GPQA 85.5% — уровень топовых проприетарных моделей, при этом активирует всего 10B параметров на токен.
GLM-4.6V — мультимодальная модель для работы с изображениями и текстом, 32B активных параметров из 106B общих, контекст до 128K.
Llama 4 Scout — самая лёгкая (17B активных), но с лучшей мультимодальностью: DocVQA 94.4%, ChartQA 88.8%.
Скорость генерации на RTX PRO 6000
Мы замерили скорость генерации (tokens/sec) при разной длине входного промпта. Каждая модель генерировала до 2048 токенов.
| Модель | Промпт | Prompt tok | Compl tok | Время (с) | tok/s |
|---|---|---|---|---|---|
| Qwen3.5-122B-A10B | Короткий | 59 | 2048 | 26.54 | 77.18 |
| Qwen3.5-122B-A10B | Средний | 496 | 2048 | 26.4 | 77.56 |
| Qwen3.5-122B-A10B | Длинный | 2144 | 2048 | 26.6 | 77.0 |
| GLM-4.6V | Короткий | 63 | 2048 | 23.45 | 87.32 |
| GLM-4.6V | Средний | 472 | 2048 | 23.14 | 88.52 |
| GLM-4.6V | Длинный | 1908 | 2048 | 23.18 | 88.34 |
| Llama 4 Scout | Короткий | 55 | 946 | 16.36 | 57.82 |
| Llama 4 Scout | Средний | 431 | 796 | 15.45 | 51.53 |
| Llama 4 Scout | Длинный | 1890 | 1152 | 21.4 | 53.84 |
Несколько наблюдений:
Qwen и GLM во всех тестах сгенерировали ровно 2048 токенов — это лимит
max_tokens, заданный при запросе. Модели были остановлены принудительно. Llama 4 Scout завершала генерацию раньше (946–1152 токенов), самостоятельно выдавая токен конца ответа.
- GLM-4.6V — самая быстрая на одиночных запросах: стабильные 87–88 tok/s независимо от длины промпта
- Qwen3.5-122B — стабильные 77 tok/s. Длина промпта практически не влияет на скорость decode
- Llama 4 Scout — 52–58 tok/s, заметно медленнее. Модель часто завершает генерацию раньше лимита в 2048 токенов
- У всех трёх моделей длина входного промпта почти не влияет на скорость генерации — prefill на RTX PRO 6000 очень быстрый
Throughput: параллельные запросы
Ключевой тест для продакшена — как модель справляется с несколькими одновременными запросами. Мы отправляли 1, 4, 8 и 16 параллельных запросов и замеряли суммарный throughput.
| Модель | 1 запрос | 4 запроса | 8 запросов | 16 запросов |
|---|---|---|---|---|
| Qwen3.5-122B-A10B | 67.7 tok/s | ~195 tok/s | ~331 tok/s | ~486 tok/s |
| GLM-4.6V | 74.7 tok/s | ~263 tok/s | ~322 tok/s | ~377 tok/s* |
| Llama 4 Scout | 63.6 tok/s | ~137 tok/s | ~180 tok/s | ~304 tok/s |
* GLM-4.6V ограничена 8 параллельными запросами (
--max-num-seqs 8) из-за большого объёма активных параметров (32B). При 16 запросах vLLM обрабатывает их в два батча: первые 8 завершаются за ~11 секунд, остальные 8 ждут в очереди и завершаются за ~24 секунды. Указанные ~377 tok/s — это throughput первого батча.
Qwen3.5-122B-A10B масштабируется лучше всех: суммарный throughput растёт почти линейно до 16 запросов. Это следствие MoE-архитектуры с всего 10B активных параметров — каждый запрос потребляет мало compute, и GPU эффективно батчит их.
GLM-4.6V быстрее всех на одном запросе, но упирается в лимит 8 параллельных запросов. Для сценариев с высокой конкурентностью это ограничение.
Llama 4 Scout — самая медленная при батчинге. Уже при 4 запросах скорость на запрос падает почти вдвое (34 vs 64 tok/s). W4A16 квантизация тяжелее для compute, чем NVFP4.
Утилизация GPU при инференсе: почему 100% нагрузки ≠ 100% энергопотребления
Если вы посмотрите на nvidia-smi во время инференса LLM, то увидите интересную картину: утилизация GPU показывает 100%, но энергопотребление составляет всего 300–400 Вт при TDP 600 Вт. Почему так происходит?
Вот реальный вывод nvidia-smi с нашего сервера во время инференса Qwen3.5-122B:
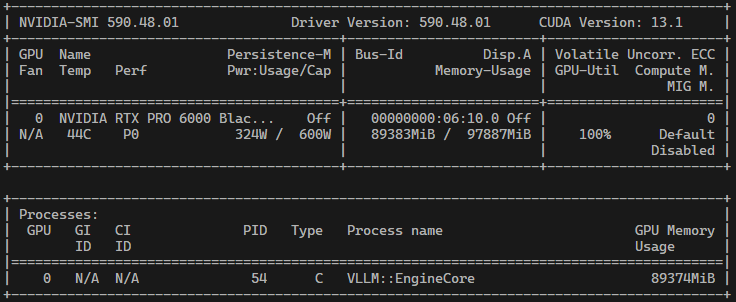
| Параметр | Значение |
|---|---|
| GPU-Util | 100% |
| Power | 324W / 600W (54% от TDP) |
| VRAM | 89 383 MiB / 97 887 MiB (91.3%) |
| Температура | 44°C |
| Driver | 590.48.01 |
| CUDA | 13.1 |
GPU загружен на 100%, но потребляет чуть больше половины от максимума. Температура при этом всего 44°C. Почему?
Что на самом деле показывает GPU Utilization
Метрика "GPU Utilization" в nvidia-smi — это процент времени, в течение которого хотя бы одно CUDA-ядро выполняло какую-либо операцию. Это не показатель того, насколько эффективно используются все вычислительные ресурсы GPU.
Можно получить 100% GPU Utilization, просто читая и записывая данные в память, не выполняя при этом ни одной математической операции. Это подтверждается исследованием Trainy: команда обнаружила, что при 100% утилизации GPU реальная эффективность использования вычислительных ресурсов (MFU — Model FLOPS Utilization) составляла всего 20%.
Почему инференс LLM — это memory-bound задача
Инференс LLM состоит из двух фаз:
-
Prefill (обработка промпта) — все входные токены обрабатываются параллельно. Это compute-bound фаза: GPU активно использует тензорные ядра, энергопотребление близко к TDP.
-
Decode (генерация) — токены генерируются по одному. На каждом шаге GPU должен:
- Загрузить все веса модели из VRAM в вычислительные блоки
- Загрузить KV-кеш для всех предыдущих токенов
- Выполнить относительно небольшое количество вычислений
- Записать результат обратно
На фазе decode узкое место — пропускная способность памяти, а не вычислительная мощность. GPU тратит большую часть времени на ожидание данных из VRAM, а не на вычисления. Вычислительные ядра простаивают, ожидая данных.
Связь с энергопотреблением
Энергопотребление GPU складывается из:
- Динамическая мощность — потребляется при активных вычислениях на CUDA/Tensor-ядрах. Пропорциональна нагрузке на вычислительные блоки.
- Статическая мощность — базовое потребление чипа (токи утечки, контроллер памяти, шина PCIe и т.д.)
- Мощность подсистемы памяти — потребление GDDR7-чипов при чтении/записи
При инференсе LLM на фазе decode:
- Тензорные ядра загружены лишь частично (низкая арифметическая интенсивность)
- Подсистема памяти работает на полную мощность (bandwidth saturated)
- Динамическая мощность вычислительных блоков значительно ниже максимума
Поэтому при TDP 600 Вт реальное потребление составляет 300–400 Вт: подсистема памяти потребляет свою долю, но вычислительные блоки не нагружены на максимум.
Аналогия
Представьте конвейер на заводе. У вас 100 рабочих (CUDA-ядра), но детали (данные) подвозят на одном грузовике (memory bandwidth). Рабочие стоят и ждут, пока грузовик привезёт следующую партию. Формально конвейер работает на 100% (всегда есть хотя бы один рабочий, который что-то делает), но реальная производительность ограничена скоростью доставки деталей.
Что это значит на практике
- 100% GPU Utilization при инференсе — это нормально, но не означает, что GPU работает на пределе вычислительных возможностей
- Энергопотребление 50–70% от TDP при инференсе — тоже нормально и ожидаемо для memory-bound задач
- Для повышения реальной эффективности нужно увеличивать batch size (больше запросов одновременно), что повышает арифметическую интенсивность
- RTX PRO 6000 с bandwidth 1792 ГБ/с — одна из лучших карт для инференса именно благодаря высокой пропускной способности памяти
Заключение
NVIDIA RTX PRO 6000 Blackwell — серьёзный инструмент для инференса нейросетей. 96 ГБ GDDR7 позволяют запускать модели, которые раньше требовали серверных GPU уровня A100/H100. Архитектура Blackwell с 5-м поколением тензорных ядер и поддержкой FP4 делает инференс квантизированных моделей ещё эффективнее.
Наши тесты показали, что на одной RTX PRO 6000 можно получить до 88 tok/s на одиночном запросе (GLM-4.6V) и до 486 tok/s суммарного throughput при 16 параллельных запросах (Qwen3.5-122B). Это позволяет обслуживать десятки пользователей одновременно с одной видеокарты.
Мы разобрали конфигурацию vLLM для каждой модели, объяснили формулу расчёта KV-кеша и почему приходится ограничивать контекст для стабильной работы, а также показали, почему 100% утилизация GPU при инференсе не означает 100% энергопотребления.